Training LLMs: Compressing the internet to a math equation

Large Language Models (LLMs) like GPT can be simplified as “internet document simulators.” They learn patterns from massive text corpora — sometimes on the scale of hundreds of billions or even trillions of tokens — so that they can predict the next token in a sequence. This article will walk you through how such base models are created, referencing the key stages: gathering and preprocessing text from the internet, tokenizing that text, training a neural network to predict tokens, and finally using the trained model to generate new text. We will also explore how these base models, although already impressive, are often just the starting point for building truly helpful assistant models.
1. Download and Preprocess the Internet
The first step to building a base model is to acquire text data — lots of it. Researchers scrape websites, forums, digitized books, online encyclopedias, and any other text source they can find. The objective is to compile a dataset large and diverse enough to capture the full breadth of natural language as used across the internet. Preprocessing typically involves removing duplicate passages, filtering out low-quality or corrupt text, and segmenting the data into manageable chunks. This is where common text repositories, like those shared on platforms such as Hugging Face, come in handy.
By the end of this phase, you have an enormous collection of raw text. However, a neural network can’t read text in its raw form — it needs numeric representations. That brings us to the second stage: tokenization.
2. Tokenization : Words to numbers
After we’ve gathered and preprocessed all the text from the internet, the next step is to convert that raw text into a format our language model can understand. This begins with tokenization, which breaks down text into smaller, manageable pieces called tokens — much like breaking a giant puzzle into individual pieces.
Early methods treated each word as a single token, but modern approaches, like subword tokenization (or byte-pair encoding), go a step further by splitting words into smaller chunks if needed. This means that even if the model encounters a rare or completely new word, it can still understand it by relying on familiar sub-parts.
For example:
Take the sentence: “Tokenization is fun!”
A subword tokenizer might split it into:
- Token 1: “Token”
- Token 2: “ization”
- Token 3: “ is”
- Token 4: “ fun”
- Token 5: “!”
Here, “Tokenization” is divided into “Token” and “ization,” ensuring the model recognizes parts of the word even if it hasn’t seen the whole word before.
But tokenization is only half the story. Once the text is split into tokens, we need to convert these tokens into numbers — a format that our model can process. This is achieved using a pre-defined vocabulary, which is essentially a specialized dictionary mapping each token to a unique number. Think of this vocabulary as a secret codebook that assigns every token a specific numerical identifier.
For instance, using our vocabulary, the tokens from our sentence might be mapped as follows:
- “Token” → 4421
- “ization” → 2860
- “ is” → 382
- “ fun” → 2827
- “!” → 0
So, the sentence “Tokenization is fun!” is transformed into a series of numbers: 4421, 2860, 382, 2827, 0. This mapping process standardizes the diverse language of the internet into a uniform numerical format, making it efficient for the model to learn from and process the data.
By converting text into tokens and then into numbers, we ensure that our model can decode the vast and varied language of the internet, one numerical piece at a time.
As an example, tiktokenizer plays a crucial role in training models by efficiently converting raw text into a standardized sequence of numerical tokens using a pre-defined vocabulary, enabling our models to learn from the vast complexity of language with ease.
3. Numbers to embeddings: Unlocking Meaning for computers
Tokens generated in the previous step serve as keys in a dynamic lookup process to retrieve their corresponding embedding vectors. Imagine the embedding matrix as a giant, learnable table where each row is a distinct token’s numerical signature.
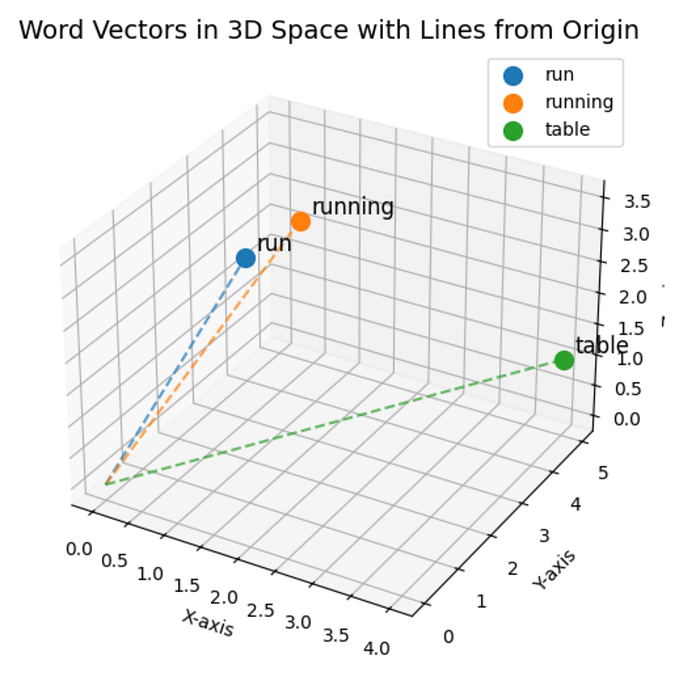
For example, consider the words “cat,” “kitten,” and “table.” Initially, these words might have random embedding vectors, but as model training progresses, their vectors start to reflect semantic similarities. “Cat” could be represented by a vector like [0.21, -0.13, 0.68], while “kitten,” being a smaller or younger cat, might have a similar vector, say [0.20, -0.14, 0.70]. In contrast, “table” — a word with a completely different meaning — might have a vector such as [0.55, 0.32, -0.47].
This transformation from simple numbers to rich, multidimensional representations allows the neural network to truly “understand” the text, moving beyond mere symbols to a deeper, more nuanced grasp of language.
4. Neural Network Training
Starting with Embeddings
Imagine you have the sentence “The cat sat on the mat.” Each word in this sentence is broken down into tokens and then converted into an embedding. These embeddings capture some of the meaning of the words and are the starting point for our model.
The Role of Self-Attention
At the core of the Transformer model is the self-attention mechanism. This allows every token to “look at” every other token in the sequence to gather context. Here’s how it works step by step:
a. Creating Queries, Keys, and Values
For each token embedding, the model computes three new vectors using learned weight matrices:
- Query (Q)
- Key (K)
- Value (V)
For example, if you take the embedding for “cat”:
- The Query might capture what “cat” is looking for in its context.
- The Key for every word tells the model what information that word holds.
- The Value carries the actual information to be shared.
This process is like preparing an information request (Query) and a set of responses (Keys and Values) that other tokens provide.
b. Calculating Attention Scores
Next, the model compares these vectors. For each pair of tokens, it computes a score by taking the dot product between the Query of one token and the Key of another. This score indicates how much attention the first token should pay to the second. To keep these scores stable, they’re scaled by the square root of the dimension of the key vectors.
c. Softmax Normalization
Once we have these scores, a softmax function turns them into probabilities. This means that for a given token, the model now has a set of attention weights — a distribution showing which words in the sentence are most important for understanding that token.
d. Weighted Sum of Values
Finally, each token’s output is computed by taking a weighted sum of all the Value vectors, using the attention weights. This creates a new, context-aware representation for each token. For instance, the representation for “cat” now includes information about “sat” and “mat,” helping the model understand that it’s not just about a cat, but about an action and location too.
Multi-Head Attention
Instead of having a single set of attention calculations, the model uses multiple “heads.” Each head processes the embeddings in a slightly different way, allowing the model to capture various kinds of relationships (like syntax, semantics, or even long-distance dependencies). The outputs from all these heads are then combined and projected back into a single vector for each token.
Feed-Forward Layers and Residual Connections
After self-attention, the model passes each token’s new representation through a feed-forward neural network. This network applies non-linear transformations (like ReLU) to help the model learn complex patterns.
- Residual Connections:
To keep the learning stable, the model adds the original input of the attention or feed-forward block back to its output. This “skip connection” helps the model train deeper networks without the gradients vanishing or exploding. - Layer Normalization:
The outputs are normalized to ensure that the scale of the activations remains consistent across layers, which further stabilizes training.
Stacking the Layers
Transformers consist of multiple layers (or blocks) that repeat the self-attention and feed-forward processes. Each layer builds on the previous one, refining the token representations. Think of it as gradually moving from simple word meanings to understanding full sentences and even paragraphs.
Training the Model
Now that we have a clear picture of how a Transformer processes a sentence, let’s see how it learns:
a. Defining the Task
Suppose our training task is next-word prediction. The model is given a sentence with a missing word and must predict what comes next. For our sentence “The cat sat on the ___,” the correct answer is “mat.”
b. Calculating Loss
The model generates a probability distribution over its vocabulary for the missing word. It then compares this prediction to the actual word using a loss function (often cross-entropy loss). The loss quantifies how far off the prediction is from the truth.
c. Back-Propagation
Using the loss, the model computes gradients — these are like signals that tell the model how to adjust its internal weights (in the attention layers, feed-forward networks, etc.) to improve its predictions. This process is known as back-propagation.
d. Updating Weights
Finally, an optimizer (such as Adam) uses these gradients to update the model’s weights. Over many iterations and with vast amounts of data, the model gradually learns to understand and generate language more accurately.
5. Inference (Generating Text One Token at a Time)
With a fully trained model, you can now generate text by feeding it an initial prompt and letting it sample one token at a time. The output token is fed back in as part of the input for the next prediction, and so on — an iterative process. For example, after seeing the first few tokens (91, 860, 287, 11579), the model might predict token 3962 is the best continuation. Then, with the updated context (860, 287, 11579, 3962), it predicts the next token, and so on.
This incremental approach to text generation allows GPT to produce coherent paragraphs, simulate conversations, or even re-create snippets that resemble specific styles of writing. Because it’s effectively sampling from a probability distribution, the exact outputs can vary — making the process both creative and unpredictable.
6. The Base Model: An “Internet Document Simulator”
When a GPT model finishes pre-training, we call it a base model. We dubbed it as an “internet document simulator” because it has absorbed so many patterns from online text that it can generate or “dream up” content resembling everything from news articles to code snippets. However, it’s fundamentally a next-token predictor — it doesn’t inherently know it should provide concise answers, follow instructions, or refrain from generating inappropriate content.
Models like GPT-2 or Llama 3.1 (with hundreds of billions of parameters) exemplify base models in the wild. They’re typically released as a combination of two elements:
- The code for running the Transformer (often a few hundred lines in Python).
- The parameters — billions of floating-point numbers that hold the learned “knowledge” from pretraining.
You can prompt a base model to do things like translate text or answer questions, but remember that it’s just predicting the most likely token continuation. It’s not guaranteed to yield carefully curated or polite responses because it lacks explicit alignment with human instructions or safety guidelines.
7. From Base Model to Assistant Model
A base model can be astonishing in its generative prowess, but real-world applications demand a system that interacts helpfully with users. That’s where assistant models come in.
Assistant models undergo additional training or fine-tuning steps — using human-labeled examples, reinforcement learning from human feedback (RLHF), or instruction fine-tuning datasets — so that they learn how to respond in a more aligned and user-friendly way. This process might involve showing the model thousands of question–answer pairs, then reinforcing patterns where the model’s output is especially helpful or correct.
8. Compressing the internet isn’t easy
Pretraining is an epic feat of data gathering, computational power, and algorithmic sophistication. The result — a base model — can appear uncannily fluent in countless subjects, but it’s not necessarily an ideal conversational agent. By applying specialized training methods, developers transform base models into assistants that can navigate user queries more thoughtfully and responsibly. This layered approach is why GPT and other LLMs have not only redefined what computers can write, but have opened doors to interactive, human-like dialog systems that continue to evolve at a rapid pace!